| Introducción | Organización | Aspectos Metodológicos |
| Control de Calidad | Conceptos y Definiciones | Resultados Principales |
| Encuesta de Cobertura | Perfiles Agropecuarios | Tabulados por Mapa |
ENCUESTA DE COBERTURA
Antecedentes
En la planificación del Tercer Censo Nacional Agropecuario (III CENAGRO) se previó la realización de una encuesta post censal para verificar la cobertura del censo. Durante el mes de marzo del 2001 se realizó el levantamiento de la información del Tercer CENAGRO. Inmediatamente, después de culminada esta labor se diseñó la Encuesta de Cobertura. Esta etapa comprendió el diseño general de la encuesta así como el diseño de muestreo en particular. El diseño general de la encuesta incluyó el conjunto de métodos y procedimientos concernientes a las diferentes fases operativas de la encuesta: diseño de muestreo, selección y entrenamiento del personal, formularios, manuales, aspectos cartográficos, organización del trabajo de campo, etc.
Objetivos
La detección y evaluación de la magnitud de los errores no muestrales es un aspecto esencial de toda investigación estadística. Los errores de este tipo en un censo pueden clasificarse en: “errores de cobertura” y “errores de respuesta”. Los primeros se refieren a la existencia de Explotaciones Agropecuarias que deberían haberse censado y no lo fueron (subcobertura) o a unidades censadas que no deberían haberlo sido (sobrecobertura); los segundos, tienen persos orígenes: errores del propio informante; errores de registro, errores de interpretación de lo declarado por el informante, errores de unidades de medida, etc..
La imposibilidad práctica de realizar mediciones objetivas durante el desarrollo de la encuesta de cobertura hizo que la encuesta post censal se refiriera solamente al análisis de la cobertura del III CENAGRO.
Diseño Muestral
MarcoA efectos del levantamiento del Tercer Censo Nacional Agropecuario el país se pidió en 2984 Segmentos de Empadronamiento Agropecuario(SEA), cada uno de los cuales conforman espacios compactos de terreno que abarcan, en promedio, algo menos de 70 Explotaciones Agropecuarias. Los 15 Departamentos y dos Regiones Autónomas del país, se subpiden en 151 Municipios que, a los efectos del Censo, se subpidieron en 956 Áreas de Supervisión y éstas, en los 2984 SEA's ya mencionados.
A efectos de la Encuesta de Cobertura se seleccionaron SEA's como conglomerados, es decir que estas Unidades de Muestreo fueron “barridas” por el enumerador de la encuesta de cobertura. Para ello se le proveyó de los mapas de los SEA's seleccionados donde se eliminaron las explotaciones agregadas por el enumerador censal durante el levantamiento de la información en campo, a efectos de aumentar la objetividad del ejercicio.
De acuerdo con los recursos disponibles, se tomó una muestra de aproximadamente el 4% de los SEA's y mediante un diseño de muestreo estratificado por conglomerados monoetápico se entrevistó a todas las Explotaciones Agropecuarias que se encontraron en los SEA's seleccionados. Se excluyeron del marco muestral los SEA's siguientes:
De los Municipios de Morrito, El Almendro, San Miguelito, y San Juan del Norte del Departamento de Río San Juan;
De los Municipios de La Cruz de Río Grande, Desembocadura del Río Grande, Laguna de Perlas, El Tortuguero, Kukra-Hill, Corn Island, Bluefields, Muelle de los Bueyes, El Ayote y Nueva Guinea correspondientes a la Región Autónoma del Atlántico Sur (RAAS);
De los Municipios de Waspán, Puerto Cabezas, Rosita, Bonanza, Prinzapolka y Waslala de la Región Autónoma del Atlántico Norte (RAAN).
Estos SEA’s no se incluyeron porque comprenden menos del 13% de las Explotaciones Agropecuarias (de manera que errores de cobertura allí influyen muy poco en el error total) siendo zonas de muy difícil acceso y se consideró más eficiente volcar esos recursos a relevar información de las áreas más importantes desde el punto de vista de los objetivos de la encuesta.
Los municipios excluidos del marco representan un total de 356 SEA's. Por tanto, el marco de SEA's a considerar comprendió finalmente 2628 unidades primarias de muestreo. La tasa general de muestreo indicada mas arriba lleva a que se seleccionaran 100 SEA's a ser encuestadas. La muestra total, comprendió 7274 explotaciones encuestadas.
Muestra
Los SEA's del marco muestral se estratificaron en 4 estratos de acuerdo con características de uso actual del suelo que surge del censo, a saber:
ESTRATO 1: PASTOS NATURALES Y PASTOS CULTIVADOS O SEMBRADOS.
Definición: Comprende pastos mejorados, pastos con malezas y tacotales asociados con vegetación arbustiva. Son áreas dedicadas fundamentalmente a la ganadería extensiva.
ESTRATO 2: CULTIVOS ANUALES O TEMPORALES.
Definición: Comprende la vegetación de cultivos de ciclo corto. Son áreas dedicadas a cultivos de granos básicos, tabaco y otros cultivos de ciclo menor a un año. Comprenden los valles intramontanos y laderas. Son, generalmente, zonas de pequeñas Explotaciones Agropecuarias.
ESTRATO 3. CULTIVOS PERMANENTES.
Definición: Comprende la vegetación de cultivos de ciclo largo. Incluye las plantaciones de café ya sea bajo sombra o expuestas al sol, cítricos, otros árboles frutales.
ESTRATO 4: OTROS.
Definición: Se clasificaron en este estrato los SEA's que no puedan ser clasificados claramente en alguno de los estratos anteriores por presentar una gran combinación de tipos de uso del suelo.
Este criterio de estratificación se adoptó por la alta correlación existente entre uso del suelo y tamaño de las explotaciones de manera que los estratos así definidos permitirían estimar errores de cobertura separadamente para grupos de sectores que presentan diferencias en el tipo de explotación preponderante (diferencias por uso del suelo y por tamaño predominante de sus explotaciones). Generalmente diferentes porcentajes de cobertura se observan asociados a estas características.
Se tomó una Muestra Aleatoria Estratificada con asignación proporcional. Esta muestra luego se post-estratificó por tamaño de las explotaciones.
Estimadores
A efectos de estimar los errores de cobertura debe tenerse en cuenta, que el número de las explotaciones detectadas en la Encuesta de Cobertura se debe tomar como el “verdadero”, es decir las explotaciones post enumeradas son las que efectivamente deberían haberse censado.
Una vez levantada la encuesta de post enumeración, se pueden dar alguna de las siguientes tres situaciones:
Concordancia entre lo observado en la encuesta de post enumeración y el censo, es decir que la Explotación Agropecuaria detectada en la encuesta de post enumeración fue correctamente censada, en este caso la explotación fue “correctamente incluida” en el censo;
La Explotación Agropecuaria identificada en la encuesta de post enumeración no fue censada, se caracterizará como explotación “erróneamente excluida”, el conjunto de estas explotaciones erróneamente excluidas constituyen la “subcobertura”;
La unidad censada (no sería en este caso una Explotación Agropecuaria) no es identificada en la encuesta de post enumeración, en este caso fue “erróneamente incluida”, el conjunto de estas situaciones constituyen la “sobrecobertura”.
De acuerdo con las definiciones anteriores:
Sean:
C = Número de explotaciones correctamente incluidas
E = Número de explotaciones erróneamente excluidas
I = Número de explotaciones erróneamente incluidas
T = Total de explotaciones que deberían haberse censado
U = Total de explotaciones censadas.
Se dan las siguientes relaciones:
C + E = T
I + C = U
Por tanto:
U-T = I-E = error neto de cobertura
El problema del error neto de cobertura es que compensa situaciones de sobrecobertura y subcobertura, es decir compensa errores. Por ello se define el error bruto de la siguiente manera [1] :
Para cada explotación j se definen dos variables aleatorias:
Por ejemplo, si la j-esima unidad es una explotación correctamente incluida, ambas variables valen 0. Si es una explotación erróneamente excluida entonces Zj = 0 y Xj = 1 y si fue erróneamente incluida Zj = 1 y Xj = 0.
Con las definiciones anteriores y referida a la muestra, la suma de las diferencias Xj - Zj dará el error neto de cobertura. Para evitar que los errores se compensen, se define el error bruto de cobertura como:
Error bruto de cobertura = Sj (Xj - Zj )2
A partir del diseño de muestreo adoptado se pueden estimar ambos errores para cada estrato y para el total del país.
Dado el diferente tamaño de los conglomerados (SEA’s) y el conocimiento que, una vez realizado el censo, se tiene de las explotaciones efectivamente censadas (U) se utilizará un estimador de razón para la estimación de C (correctamente incluidas o concordancias), y por tanto la estimación de la sobrecobertura (I): I = U-C.
Sean:
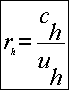
donde ch es el total de concordancias en la muestra del estrato h y uh el total de censadas encontradas en la muestra del estrato h (bien o mal censadas).
Entonces el estimador de razón de las explotaciones correctamente incluídas es:
![]()
siendo Uh el número de explotaciones realmente censadas en el estrato h.
De allí:
![]()
Obsérvese que U es calculado sin error de muestreo, por tanto la única fuente error en la estimación de la sobrecobertura (I) proviene de la estimación de las correctamente incluidas o concordantes (C).
Por otra parte, sea:
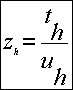
donde th es el número de encuestadas (y que deberían haberse censado) en el estrato h.
Se estima el total de explotaciones que deberían haberse censado como:
![]()
Así la subcobertura resulta estimada por:
![]()
El error neto por:
![]()
y el error bruto por:
![]()
Intervalos de confianza aproximados para estas estimaciones pueden lograrse a partir de la fórmula usual de la varianza del Muestreo Estratificado proporcional aproximando la varianza del estimador de razón de la manera conocida siempre que el sesgo pudiera ser despreciado. Esta es la situación si el coeficiente de variación del numerador de la razón es “pequeño” (menor a 0.2) [2]
Organización del Trabajo de Campo
De acuerdo con las características y objetivos de esta encuesta, no se trata de relevar información sobre las variables agropecuarias sino de identificar todas las Explotaciones Agropecuarias que deberían haberse censado. En este sentido se asignó esta tarea a los mejores funcionarios que trabajaron en el censo, con alto nivel de responsabilidad y contracción al trabajo. Estos encuestadores, frente a cada situación que se le presentara en su recorrido del área asignada debían discernir si se trataba de una Explotación Agropecuaria al momento del censo. Debían llenar la boleta del post censo y anotar todas las observaciones que luego permitieran, en la oficina, la conciliación con la boleta censal. Asimismo registrarían cuidadosamente en el mapa del SEA asignado, su recorrido y la ubicación precisa de cada explotación hallada.
Desde el punto de vista de los recursos disponibles y de acuerdo a las características previstas para la boleta de enumeración de la encuesta de cobertura, se estimó que un enumerador podría visitar entre 10 y 12 Explotaciones Agropecuarias por día por lo que tomaría entre 6 y 7 días culminar el “barrido” de un SEA. Se asignaron 50 enumeradores y cada uno de ellos relevaría dos SEA's en promedio. De acuerdo con estas estimaciones preliminares, el levantamiento de la información se realizó en dos semanas de trabajo.
Nadie trabajó en la misma área que le correspondió supervisar durante el censo. Desde el punto de la supervisión de este ejercicio, se formaron grupos de 10 SEA's de la muestra, cercanos geográficamente (independientemente del estrato al cual pertenezcan) y de tal manera que dentro de un mismo grupo estuvieran los dos SEA's que le corresponden a un mismo empadronador de post censo.
De esta manera, cada grupo de SEA's tuvo cinco empadronadores y se designó un supervisor para cada uno de estos grupos. Los supervisores fueron técnicos de la oficina del censo del INEC en Managua.
La oficina del censo fue la responsable de la capacitación para el post censo. A cada empadronador se le entregó un mapa del SEA que le correspondía relevar, estos mapas fueron confeccionados a partir de los que volvieron del campo en ocasión del censo a los cuales se les borraron las anotaciones que realizó el empadronador referidas a las Explotaciones Agropecuarias nuevas o desaparecidas, quedando copia, en la Oficina, del mapa que volvió del campo con las anotaciones del empadronador, pues luego este mapa resultaría fundamental al momento de realizar la conciliación entre los formularios.
Se diseñaron formularios de control de entregas y recepción de materiales del post censo similares a los utilizados para el censo.
Los días 5 a 7 de mayo de 2001 se realizó la encuesta piloto de la encuesta de cobertura censal. Esta encuesta piloto abarcó 14 Sectores de Empadronamiento Agropecuario en los 14 Departamentos del país no pertenecientes a las regiones atlánticas. La encuesta piloto permitió probar todo el operativo. A partir de la encuesta piloto se probaron todos los procedimientos diseñados para lograr la conciliación de la información censal y la de la encuesta (determinación de errores de cobertura), se evaluaron tiempos y se definieron las características de los programas de computación a utilizarse. A partir de los resultados de la encuesta piloto se ajustaron el formulario y el manual (En anexo se presenta el formulario y manual empleados).
El trabajo de campo de la encuesta de cobertura se realizó entre el 23 de mayo y el 10 de junio de 2001. Las tareas de conciliación y búsqueda de los correspondientes formularios censales se efectuó entre junio y octubre de 2001.
Resultados Obtenidos
Debe tenerse en cuenta que conceptualmente se tienen los dos conjuntos: El de las explotaciones censadas, cuyo número es U y surge del censo y el de las explotaciones que deberían haberse censado (es decir “las encuestadas” ya que se parte del supuesto que la encuesta de cobertura es la que las determina sin error) cuyo número T surge de la encuesta de cobertura. Como ya se dijo, la intersección de ambos conjuntos nos da el conjunto de las “correctamente incluidas” o concordancias (que son C), la diferencia entre el conjunto de las que deberían haberse censado y las concordancias nos da el conjunto de las erróneamente excluidas (E) (subcobertura), mientras que la diferencia entre el conjunto de las censadas y el de las concordantes nos da las erróneamente incluidas en el censo (I) (sobrecobertura). Por lo tanto, los porcentajes de subcobertura y de sobrecobertura tiene sentido sean calculados sobre totales diferentes: el primero sobre el total de encuestadas y el segundo sobre el total de censadas.
Las tablas siguientes presentan los porcentajes estimados de subcobertura y sobrecobertura y los correspondientes coeficientes de variación por estrato y totales.
Debe tenerse en cuenta que para efecto de la Encuesta de Cobertura las EA's efectivamente censadas son 180234 y no 199549 porque, como ya se explicó, fue excluido del marco un conjunto de municipios de la Costa Atlántica y las inferencias son válidas para la población de la cual se extrajo la muestra.
TABLA 1
Porcentajes de subcobertura y sobrecobertura
CONCEPTO |
ESTRATO 1 |
ESTRATO 2 |
ESTRATO 3 |
ESTRATO 4 |
TOTAL |
Censadas |
65005 |
45471 |
36251 |
33507 |
180234 |
Estimación de las que deberían haberse censado.( |
54738 |
34712 |
30923 |
27968 |
148341 |
Porcentaje sobre censadas |
84.2 |
76.3 |
85.3 |
83.5 |
82.3 |
Estimación de la sobrecobertura ( |
15683 |
13796 |
8735 |
9122 |
47336 |
Porcentaje sobre censadas |
24.1 |
30.3 |
24.1 |
27.2 |
26.2 |
Estimación de la subcobertura ( |
5415 |
3037 |
3407 |
3584 |
15443 |
Porcentaje sobre las que deberían haberse censado |
9.9 |
8.7 |
11.0 |
12.8 |
10.4 |
Estimación del error neto |
10267 |
10759 |
5328 |
5539 |
31893 |
Estimación del error bruto |
21098 |
16833 |
12142 |
12706 |
62779 |
En ambas razones utilizadas, el sesgo introducido por este estimador es desechable, en efecto, los coeficientes de variación de las concordancias por estrato y de las que deberían haberse censado por estrato son pequeños, como surge de las tablas siguientes:
TABLA 2
Coeficientes de variación de concordancias y encuestadas por estrato (en la muestra)
Concordanc. |
c.v |
Encuestadas |
c.v |
2450 |
0.01 |
2719 |
0.01 |
1846 |
0.02 |
2023 |
0.02 |
1260 |
0.02 |
1416 |
0.02 |
973 |
0.02 |
116 |
0.23 |
La tabla siguiente muestra los intervalos de confianza estimados al 90% para las principales magnitudes estimadas:
TABLA 3
Intervalos de confianza al 90%
Concepto |
Límite inferior | Límite superior |
| Número de concordancias | 128,173 |
137,624 |
Porcentaje de sobrecobertura |
23.6 |
28.8 |
Número de las que deberían haberse censado |
142,151 |
154,532 |
Porcentaje de subcobertura |
9.4 |
11.4 |
Como puede apreciarse, la cobertura del Tercer Censo Nacional Agropecuario ha sido muy adecuada.
Se aprecia una sobrecobertura relativamente importante del número de explotaciones pero el análisis de la misma permitió concluir que mayormente se debe a haber tomado como Explotaciones Agropecuarias parcelas o fracciones de explotaciones, por tanto su influencia en la información global no es de importancia (ya que los datos de la explotación fueron tomados). Se observa, también una subcobertura, en el número de Explotaciones Agropecuarias del 10.4%, que, como se verá a continuación, se dio fundamentalmente en omisión de explotaciones pequeñas.
Para observar el comportamiento de la cobertura del censo por tramo de tamaño de las explotaciones se post estratificó la muestra por tamaño total de las explotaciones encuestadas. Como esto se realizó sobre las encuestadas solamente, solo tiene sentido estudiar aquí la subcobertura (ya que es la diferencia entre encuestadas y concordancias).
Se observa una fuerte subcobertura de las de menos de media manzana de superficie total (37% de subcobertura para este tramo). Como se sabe las explotaciones muy pequeñas, a veces en áreas suburbanas, en zonas de fraccionamiento de tierras o agrupadas en zonas rurales son mas factibles de ser omitidas en un levantamiento censal. Estos porcentajes de subcobertura caen fuertemente a medida que se avanza en los tramos de tamaño (Véase Tabla 4).
TABLA 4
Porcentajes de subcobertura por tramo de tamaño
Tramos de tamaño (Mzs.) |
Porcentaje de subcobertura |
Hasta 0.5 |
37.0 |
De 0.51 a 5.00 |
10.3 |
De 5.01 a 10.00 |
7.9 |
De 10.01 a 50.00 |
4.2 |
De 50.01 y más |
4.5 |
Esta mayor cobertura de las explotaciones mas grandes tiene como consecuencia que en términos de área agropecuaria censada la cobertura del censo haya sido muy buena. En efecto, aplicando los porcentajes anteriores al área total censada por tramo de tamaño se concluye que se habrían omitido de ser censadas alrededor de 400,000 manzanas, lo que representa menos del 5% del área agropecuaria nacional estimada en nueve millones trescientas mil manzanas.
[1] Véase, por ejemplo Zarkovich, “Quality of statistical data”, FAO 1966.
[2] FAO. “Métodos de Muestreo para Encuestas Agrícolas” Series de Desarrollo Estadístico #3. 1989.